MEMBER RESEARCH
SpaceX AI 为什么把 Colossus 1 租给 Anthropic
保留原文结构、关键图表和上下文,让长篇 Markdown 可以像研究报告一样在网页上阅读。
来源:Mirae Asset Securities Research,
AI Bi-weekly, 2026.5.8
范围:仅翻译报告中与 SpaceX AI / xAI / Anthropic / Colossus 1 相关的长文部分,包含第 3 页的 Highlight,以及第 5-23 页的AI Player Dynamics主文。第 4 页的 Vision Banana 主题与本篇无关,未纳入。 说明:原 PDF 是图片型版式,本文基于 OCR 后人工校正翻译;图表保留为原报告截图,便于核对原始版面。
本周重点:两周内被改写的叙事,原因是 SpaceX AI 与 Anthropic 的交易
两周前,我们曾用一份报告梳理 GPT-5.5 发布的意义。当时的结论是:谁能更早、更多、更稳定地 확보算力,谁最终就会拿下这场竞争。而在 OpenAI 的 30GW 路线图压过 Anthropic 的 7-8GW 规划之后,我们也曾以「OpenAI 在算力层面取得结构性优势」作为结论。
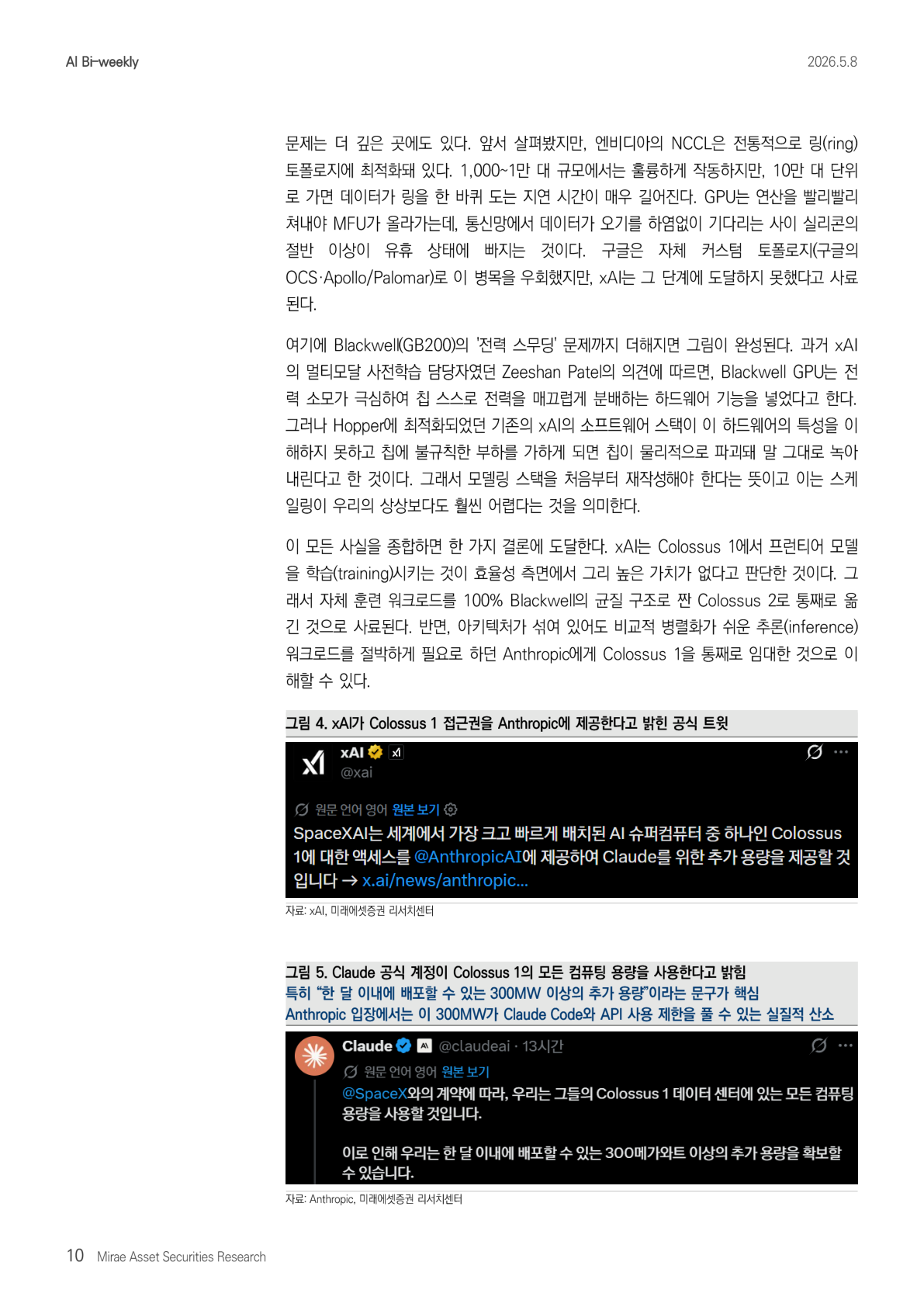
但不到半个月,这个结论就被动摇了。5 月 6 日,Anthropic 与 SpaceX AI 签署协议,将 Colossus 1 数据中心的全部容量作为单一租户整体租下。这里的 SpaceX AI,可以理解为 Elon Musk 的 xAI 与 SpaceX 结合而成的基础设施子公司。这项资产包含超过 22 万块 GPU 和 300MW 级别电力容量,更重要的是,它将在本月内投入使用。
这相当于 Anthropic 在 4 月单月累计新增 13.8GW 算力承诺后的最后一记重锤。只看表面数字,OpenAI 花了一年以上才堆出 18GW,而 Anthropic 在一个月内就拿到了 13.8GW。本次热点的核心可以概括为三点。
第一,算力差距的优势结构再次被改写。Anthropic 先后拿下 AWS 扩容 5GW、10 年超过 1000 亿美元的支出承诺、Google + Broadcom 的 3.5GW TPU、Google Cloud 的 5GW 与 400 亿美元投资,以及 SpaceX AI Colossus 1 的 0.3GW。由此,其累计承诺容量达到约 14.8GW。虽然这仍只有 OpenAI 2030 年 30GW 路线图的一半左右,但从「可上线性」角度看,SpaceX 这部分租赁容量能在一个月内投入使用,意义完全不同。
第二,Elon Musk 正是起诉 OpenAI 的原告。但与此同时,他又成了 OpenAI 最强竞争对手 Anthropic 的供应方,把超过 22 万块 GPU 和 300MW 电力整体交给了 Anthropic。尤其是这项交易发生在 Musk 与 Sam Altman 的诉讼进行期间,意味深长。我们判断,这背后存在一场围绕 OpenAI 的双线作战:Musk 在法庭上削弱 OpenAI 管理层的道德正当性,同时在市场上给 Anthropic 递武器,让 Anthropic 去吸收 OpenAI 的收入和用户。
第三,这笔交易在财务工程上是一个完整的双赢。xAI 可以通过单一合同确认每年约 60 亿美元收入,这个规模几乎刚好对冲 xAI 按 2026 年一季度年化计算的 60 亿美元净亏损。并且,在 SpaceX AI 被市场讨论以 1.75 万亿美元估值 IPO 之前,这笔交易能快速改善其财务结构。Anthropic 则有机会把 50 亿美元支出转化为 150 亿美元 ARR,获得推理收入爆发的效果。
如果两周前还被称为「OpenAI 结构性优势」的算力差距,能在这么短的时间内被改写,那么我们在这个市场里到底应该把什么认作真正的护城河?这份报告试图一步步回答这个问题。
I. AI 玩家动态
1. 两周内出现的拐点
(1) 与上一次报告相比,局面已经不同
截至 4 月 24 日我们写上一篇报告时,当时得出的结论是:OpenAI 凭借 GPT-5.5 的压倒性性能,以及更重要的 30GW 长期路线图,已经进入了算力结构性优势区间。相对地,Anthropic 把 Mythos Preview 继续维持在非公开状态,又在 Pro 计划中悄悄移除 Claude Code,暴露出算力配给的迹象,叙事迅速转弱。在这种情况下,「OpenAI 第一、Anthropic 第二」的格局,至少在未来几个月内看起来会相对稳定。
但如果重新回看最近一系列交易,风景已经完全不同。Anthropic 先是与 AWS 签下 5GW 扩容协议,累计投资达到 330 亿美元,并伴随未来 10 年超过 1000 亿美元的支出承诺;4 月 20 日,又确认了与 Google 的 3.5GW TPU + Broadcom 芯片交易;4 月 24 日,再叠加 Google Cloud 的 5GW 追加承诺和 400 亿美元股权投资。到了 5 月 6 日,SpaceX AI 的 Colossus 1 又以 0.3GW 即时上线的形式正式加入,成为这一整个月 Anthropic 抢算力行动的收官一笔。
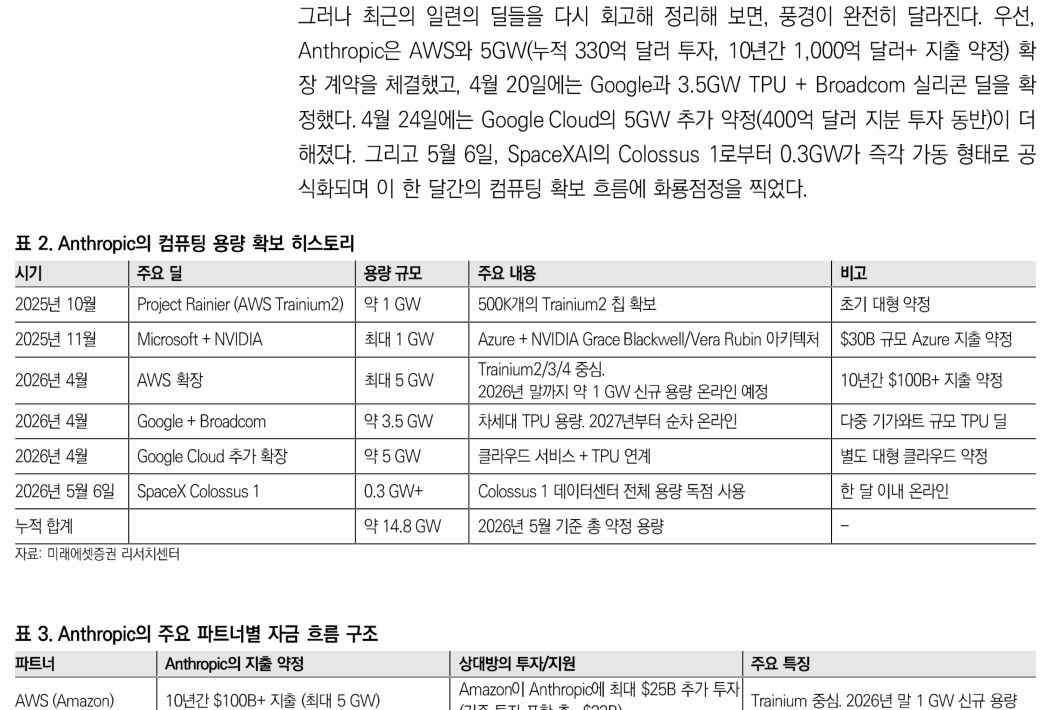
这一个月里,Anthropic 新增的承诺容量合计约 13.8GW。同期 OpenAI 新增为 0GW。OpenAI 在 18 个月内,也就是 2025 年 1 月到 2026 年 2 月之间,才积累出 18GW 的体量,其中包括 Stargate 10GW、5000 亿美元投入、AMD MI450 6GW、AWS Trainium 2GW 等。如今,这个差距在短短一个月内被迅速追赶。每次复盘这个市场,都会再次感受到它变化得实在太快。
(2) OpenAI 为什么停住了:MRC 与网络物理规律
OpenAI 在 4-5 月两个月里没有再新增哪怕 1GW,原因并不是简单的「缺资本」。他们真正要先解决的是:已经拥有的基础设施不能充分工作的难题。
5 月初,OpenAI 播客节目 MRC: A new protocol with AMD, Broadcom, Intel, Microsoft, and NVIDIA 中,加入 OpenAI 的网络专家 Mark Handley 和 Greg Steinbrecher 承认了一个相当震撼的事实。他们新开发的 MRC,也就是 Multipath Reliable Connection 协议,是从这样一个物理认知出发的:AI 训练负载是「你能想象到的、最糟糕的网络负载」。

问题核心是 P100,也就是「尾部的尾部」延迟。AI 训练不同于互联网流量。互联网里有数百万用户分别点击不同网站,流量随机分散,平均负载自然能被调节。但 AI 不是统计意义上的分散流量。10 万块 GPU 必须在完全相同的时刻完成计算,并在完全相同的时刻发起流量来同步权重。
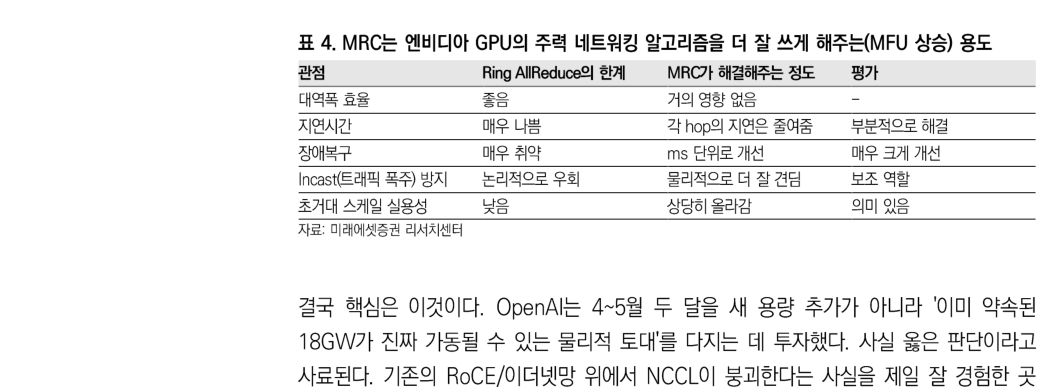
因此,网络的「平均速度」没有意义。那个最堵、最慢的单一链路,才会决定整个集群的速度。AI 网络不是看全班平均分,而是由倒数第一的分数决定全班成绩。过去,InfiniBand 或 RoCE 这类通信协议叠加 NVIDIA 开发的 NCCL 算法,还能勉强支撑规模扩展。但当超过 10 万块 GPU 需要并行同步训练时,既有 NCCL 及 Ring All-Reduce 算法就会陷入危机。

OpenAI 选择正面突破这个问题,从底层传输协议,也就是 MRC 层面动手改造,并通过 OCP,也就是 Open Compute Project,将它开放为开源标准。可以理解为,OpenAI 正试图摆脱 NVIDIA 硬件与软件生态的约束,把自己推到 AI 基础设施标准制定者的位置上。
2. xAI 的双向焦虑:SpaceX-Cursor 与 Colossus 1
(1) Cursor 600 亿美元看涨期权泄露出的自白
要理解 SpaceX AI 与 Anthropic 交易背后的图景,必须先看 4 月 24 日公布的另一笔交易:SpaceX 针对 AI 编程助手强者 Cursor 签下的 600 亿美元看涨期权协议。表面上,这笔交易是一种不对称期权结构:SpaceX 获得在今年下半年以 600 亿美元收购 Cursor 的权利;如果最终不收购,则支付 100 亿美元作为「合作费用」。
但这份协议的真正本质,是 Musk 体系承认自己在自有编程模型能力上存在缺口。OpenAI 推出 Codex 后,首日周活跃用户就突破 400 万,四个月增长 20 倍;Anthropic 则通过 Claude Code 拿走了编码智能体市场的一半。相对地,xAI 的 Grok 在编码领域始终没能达到 SOTA。再加上核心联合创始人陆续离开,业内普遍认为其自有模型训练本身也遭遇了困难。换句话说,要实现「数字 Optimus」这样巨大的目标,xAI 最终不得不借助外部力量。
于是 xAI 选择了借外部之手。Cursor 拥有年化经常性收入 20 亿美元,按 2026 年 2 月口径,5 个月内从 10 亿美元增长到 20 亿美元;它渗透了 67% 的财富 500 强企业,每天产生 1.5 亿行企业代码,也就是独占性的开发者行为数据 Developer Traces。xAI 得以把这些数据放到 Colossus 集群上训练,同时把相同配方应用到自家 Grok 上做盲测。这相当于一场实时实验:AI 编码模型真正的瓶颈到底是算力 FLOPS,还是独占数据 Traces?
总结来看,SpaceX-Cursor 期权和 SpaceX AI-Anthropic Colossus 1 租赁,其实都来自同一条根。xAI 通过这两笔交易同时承认:仅靠自家的前沿模型,很难与 OpenAI 和 Anthropic 正面竞争。但这种承认并不是软弱的失败,而更像一次战略转向:既然模型层不一定能赢,就在基础设施层开辟新的战线。
(2) Colossus 1:一个巨大的「弗兰肯斯坦集群」
xAI 决定把 Colossus 1 整体交给 Anthropic,背后的技术原因更值得玩味。xAI 在孟菲斯的 Colossus 1 数据中心部署了超过 22 万块 NVIDIA GPU。其中大约 15 万块是 H100,5 万块是 H200,2 万块是 GB200。也就是说,一个集群里混合了三种不同世代的芯片,这是一种异构架构。
但从分布式训练角度看,工程师会说这几乎接近灾难。分布式训练中,10 万块 GPU 必须同时完成一个 step,才能进入下一个 step。如果 GB200 已经完成计算,但稍慢的 H100,或者某个栈上出问题的 GPU 还没完成,其余 99,999 块 GPU 都只能等待。这被称为 straggler effect,也就是拖尾者效应。The Information 此前报道的 xAI 11% GPU 利用率,也就是 MFU,理论 FLOPS 相对实际有效 FLOPS 的比例,可以被理解为这个问题的数字化结果。相比之下,Meta 和 Google 的 MFU 已经能做到 40% 以上。
问题还更深一层。前面提到,NVIDIA 的 NCCL 传统上优化的是 ring 拓扑。在 1000 到 1 万块 GPU 规模下,它运行得很好。但进入 10 万块 GPU 规模时,数据绕 ring 一圈的延迟会变得非常长。GPU 必须持续快速计算,MFU 才能上升;但当它们在通信网络上无止境等待数据时,硅片一半以上的时间就会处于闲置状态。Google 通过自定义拓扑,也就是 OCS Apollo / Palomar,绕开了这个瓶颈;但我们认为 xAI 尚未到达这个阶段。
再叠加 Blackwell GB200 的「电力平滑」问题,图景就完整了。曾负责 xAI 多模态预训练的 Zeeshan Patel 认为,Blackwell GPU 功耗极端,因此芯片内置了用于平滑分配电力的硬件功能。但 xAI 原本为 Hopper 优化的软件栈,并不能理解这种硬件特性。如果它向芯片施加不规则负载,芯片可能物理损坏,甚至字面意义上熔毁。这意味着模型栈必须从头重写,而这也说明,规模化训练比我们想象的更难。
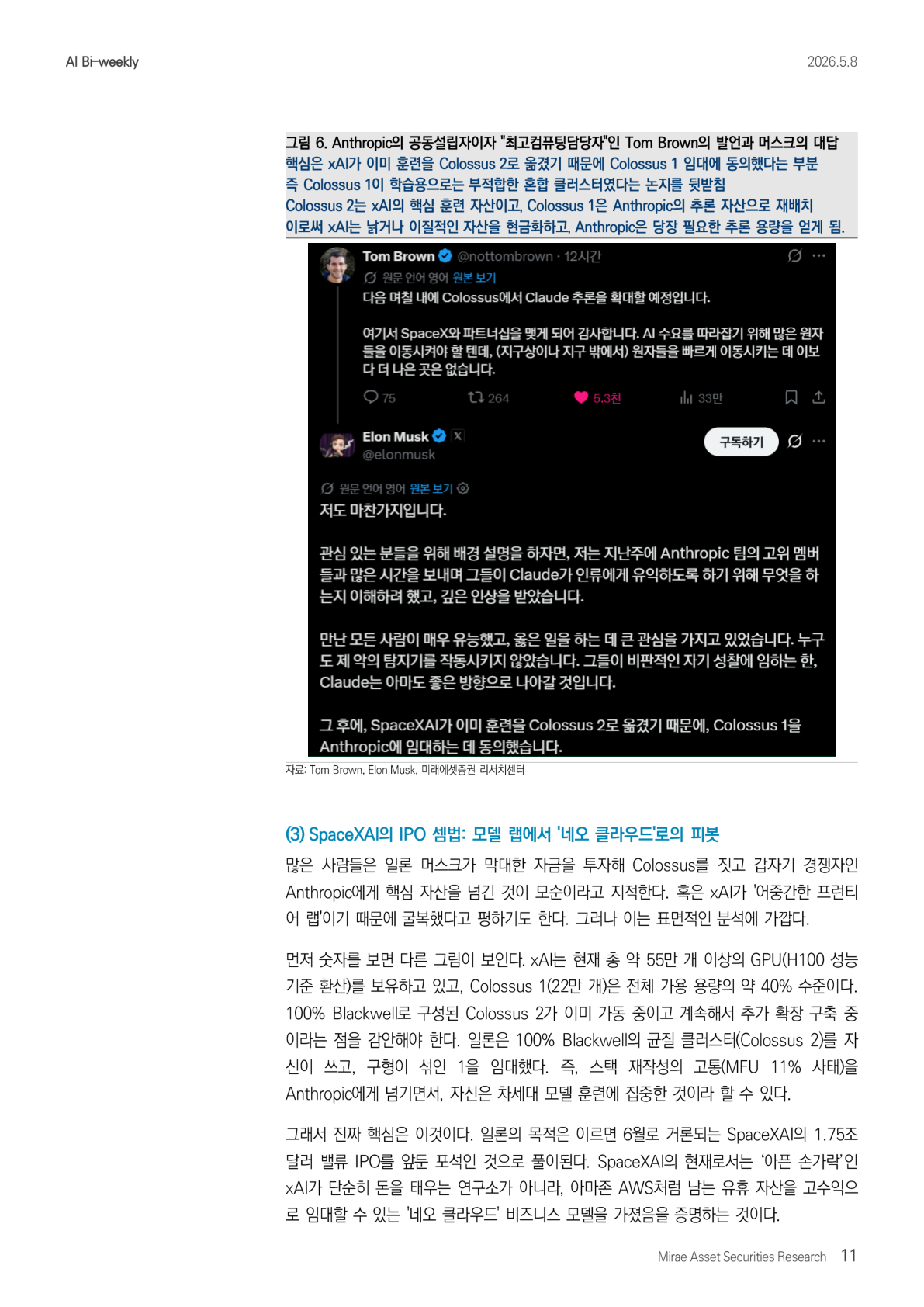
把这些事实合在一起,可以得到一个结论:xAI 判断,用 Colossus 1 训练前沿模型,从效率角度看价值并不高。所以它把自有训练工作负载整体迁移到 100% Blackwell 均质架构的 Colossus 2 上。相反,对于迫切需要推理工作负载的 Anthropic 来说,即使架构混杂,只要能更容易并行化推理任务,Colossus 1 就是合适资产。因此,xAI 把 Colossus 1 整体租给了 Anthropic。
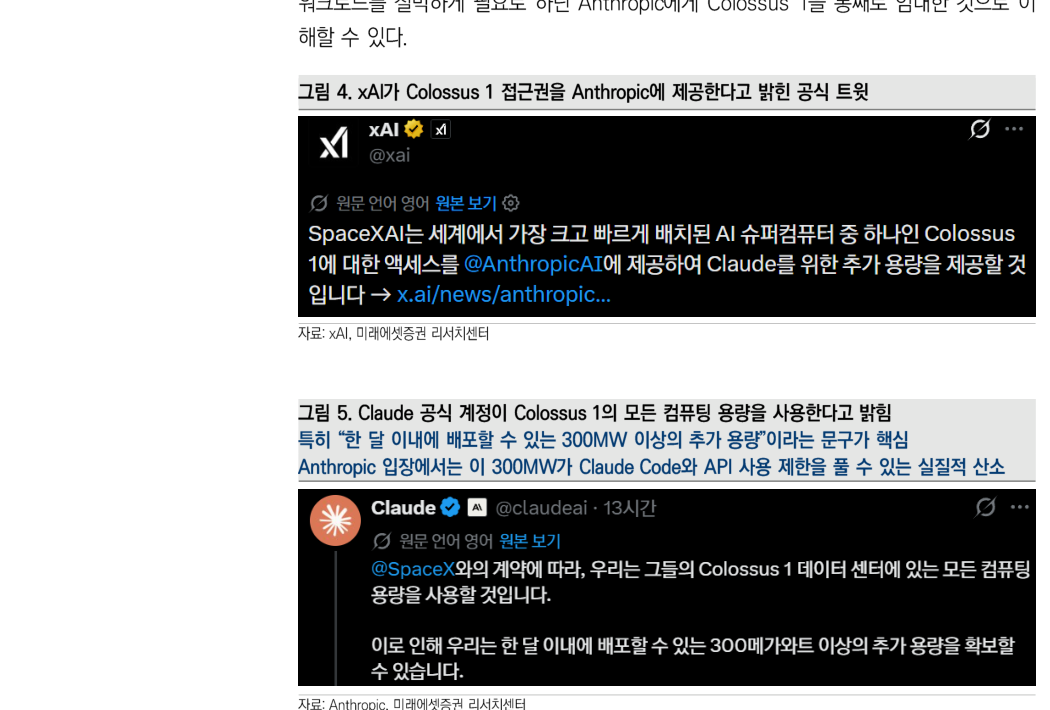
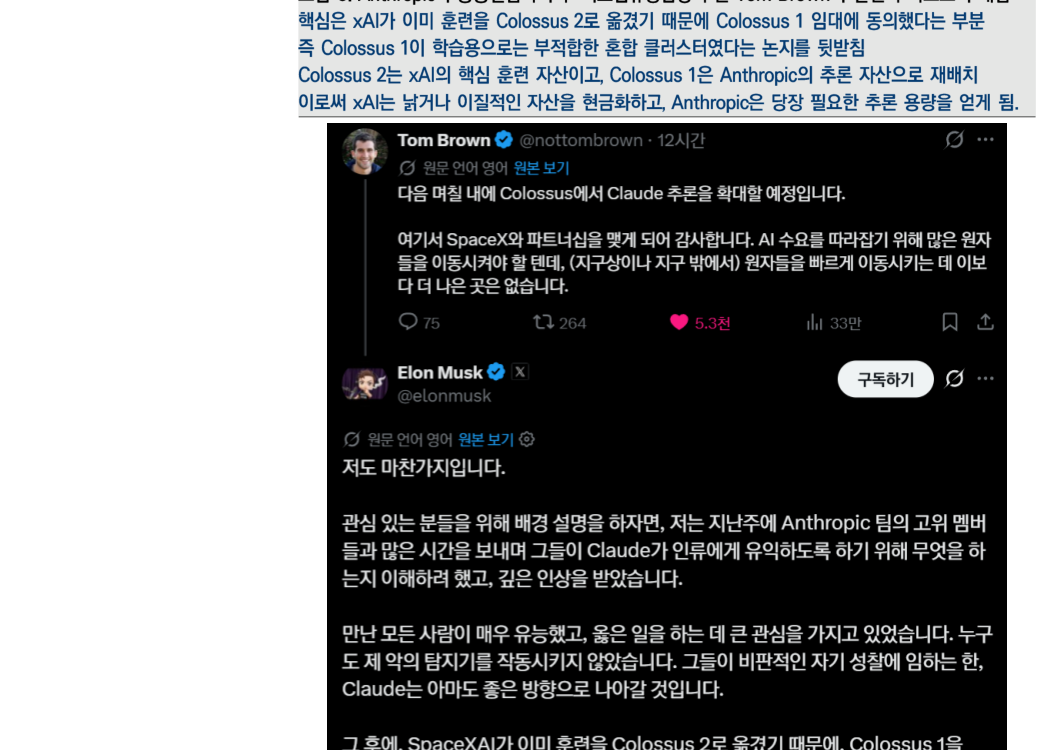
图 6 的关键点在于:Musk 表示,SpaceX AI 已经把训练迁移到 Colossus 2,因此才同意把 Colossus 1 租给 Anthropic。这支撑了前面的论点:Colossus 1 是一个不适合训练的混合集群。Colossus 2 是 xAI 的核心训练资产,而 Colossus 1 被重新配置为 Anthropic 的推理资产。这样一来,xAI 将老旧或异构资产现金化,Anthropic 则获得了当下最需要的推理容量。
(3) SpaceX AI 的 IPO 算法:从模型实验室转向「新云」
很多人认为,Musk 投入巨资建设 Colossus 后,却突然把核心资产交给竞争对手 Anthropic,是一种矛盾。也有人评价说,这是因为 xAI 作为前沿模型实验室不上不下,所以不得不低头。但这只是表层分析。
先看数字,会看到另一幅图。xAI 当前拥有的 GPU 总量,按 H100 性能折算超过 55 万块。Colossus 1 的 22 万块,约占全部可用容量的 40%。但必须注意,100% Blackwell 架构的 Colossus 2 已经开始运行,并且还在持续扩建。Musk 把 100% Blackwell 的均质集群 Colossus 2 留给自己,把混入旧款芯片的 Colossus 1 拿出去租。也就是说,他把重写软件栈的痛苦,也就是 MFU 11% 的麻烦,转移给了 Anthropic,自己则集中做下一代模型训练。
真正关键的是,Musk 的目的很可能是为最快 6 月讨论中的 SpaceX AI IPO 铺路,市场传闻估值约 1.75 万亿美元。xAI 目前是 SpaceX AI 体系里比较「让人头疼的手指」,他需要证明 xAI 不只是一个烧钱研究所,而是拥有类似 AWS 的「新云」商业模式:可以把闲置资产以高收益租出去。
从资本成本角度看,比起「制造 AGI 的吞金兽」,投资者显然更喜欢「创造现金流的数据中心出租商」。

为了 SpaceX AI 成功上市,Anthropic 也在配合这个叙事。当然,Anthropic 选择 SpaceX 并不是出于对太空的浪漫,而是出于冷冰冰的生存计算:地面电网可能在 2028 年左右完全饱和。
事实上,美国目前公布的吉瓦级基础设施建设计划,一半以上从当下看都还接近空中楼阁。要在单一地点供应超过 1GW 的电力,必须立刻进行大规模输电网扩建。但监管批准和许可流程通常至少需要 5-10 年。此外,为几十万块下一代加速器散热所需的液冷系统,以及配套水资源,也已经接近临界点。
如果再把 SpaceX 今年 4 月在得州 Grimes County 公告听证的 Terafab 项目放进来,图景会更清晰。SpaceX 将 Gibbons Creek 水库周边地区指定为 Reinvestment Zone No. 1-2026-001,计划建设一个「多阶段、下一代、垂直整合的半导体制造和高级计算设施」,也就是 Terafab。初始资本投入为 550 亿美元,如果追加阶段全部建设,总规模高达 1190 亿美元。这相当于一种声明:利用 Intel 14A 技术设计自有硅片,并从芯片、数据中心到轨道发电控制整个栈。我们可以把它理解为:Musk 在尝到 NCCL 局限之后,正在设计一条摆脱 NVIDIA 生态依赖的绕行路线。

总之,Musk 真正下注的不是模型,而是基础设施。如果 xAI 自有模型成功,那当然是最佳剧本;即使失败,它也可以作为全球 AI 基础设施的「收费站」赚钱。
3. 推理 vs 训练:租赁交易的真正机制
(1) 一个混合集群被单一租户整体接走,意味着什么
如前所述,Colossus 1 租赁合同最重要的细节是:这不是用于训练,而是用于推理。与训练不同,推理不需要 GPU 之间高度同步的通信。即便芯片种类不同,也可以把任务切分并并行分发。也就是说,原本混合集群最大的弱点,straggler effect,在推理工作负载中几乎不会被激活。
同时,Anthropic 作为单一租户整体占用 22 万块 GPU,多租户环境下产生的网络切换 jitter,也就是不可预期延迟,会消失。这是双方技术弱点互相精确补位的结构。
这里可以得到一个洞察:Colossus 1 是一个由 H100 / H200 / GB200 混合组成的集群,用于训练时按 MFU 只有 11% 的效率。但当它作为推理资产整体交给单一客户时,立刻变成可以按每小时约 2.6 美元加权平均租金出租的现金流资产。对 xAI 来说,用于训练时像「地狱集群」的东西,作为推理租赁资产时就变成每年产生 50-60 亿美元现金流的金蛋。Musk 的天才之处,可能不在模型,而在这套资产周转结构。
(2) API 限额放大 5 倍,透露了什么
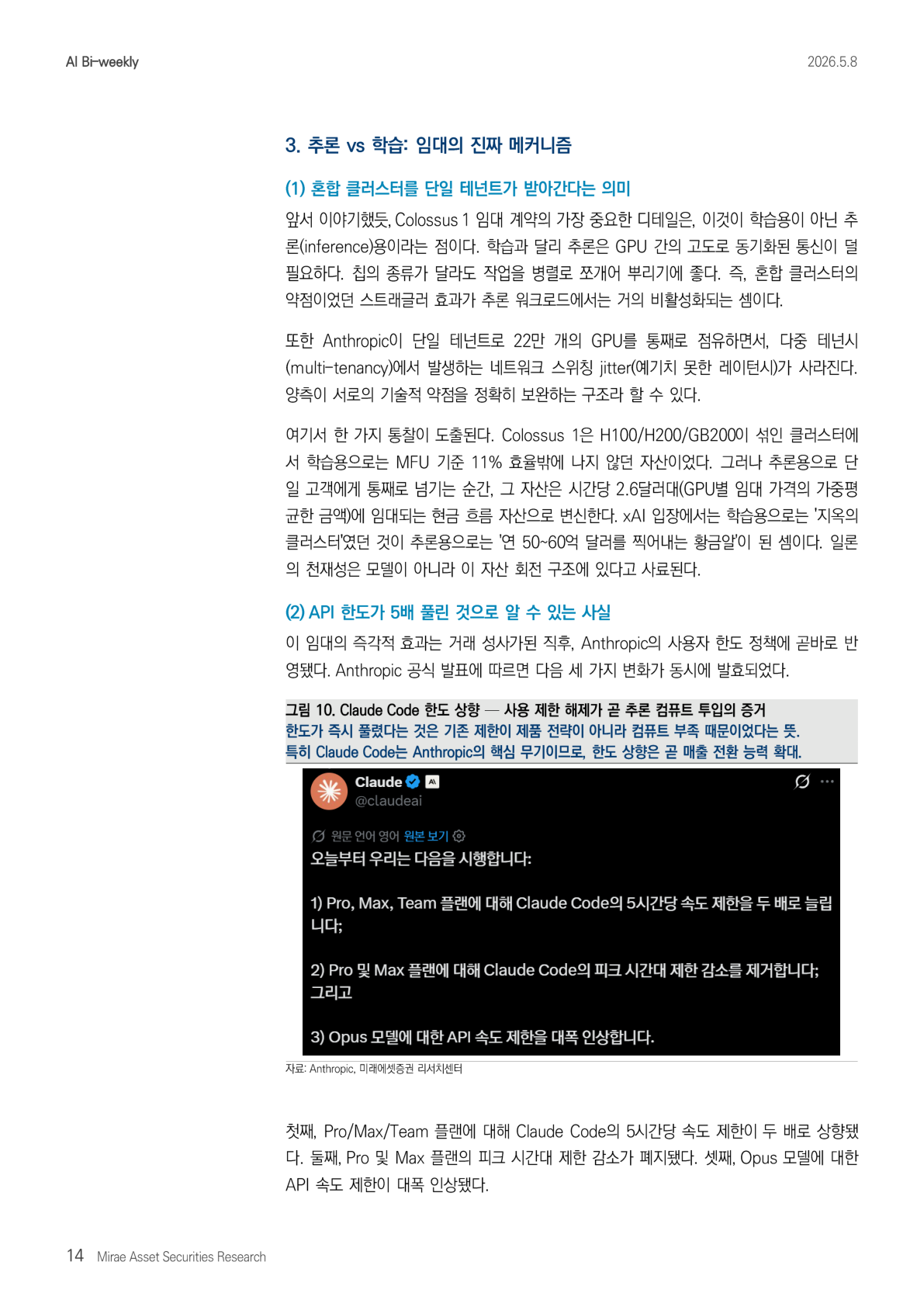
这项租赁的直接效果,在交易达成后立刻反映到 Anthropic 的用户限额政策中。根据 Anthropic 官方公告,三项变化同时生效:
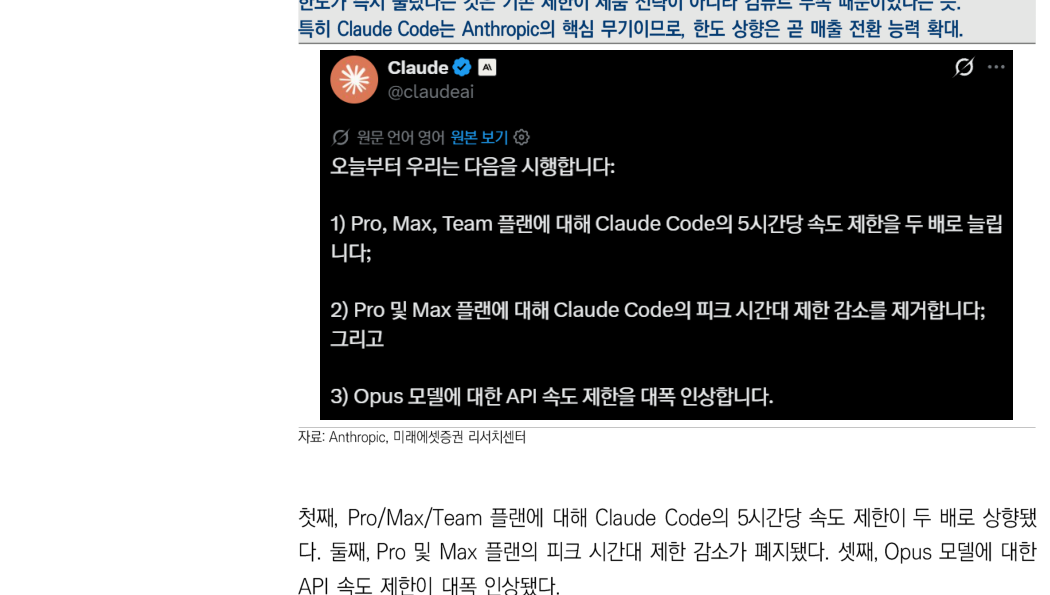
第一,Pro / Max / Team 计划的 Claude Code 每 5 小时速率限制翻倍。第二,Pro 和 Max 计划高峰时段的限制下调被取消。第三,Opus 模型 API 速率限制大幅上调。
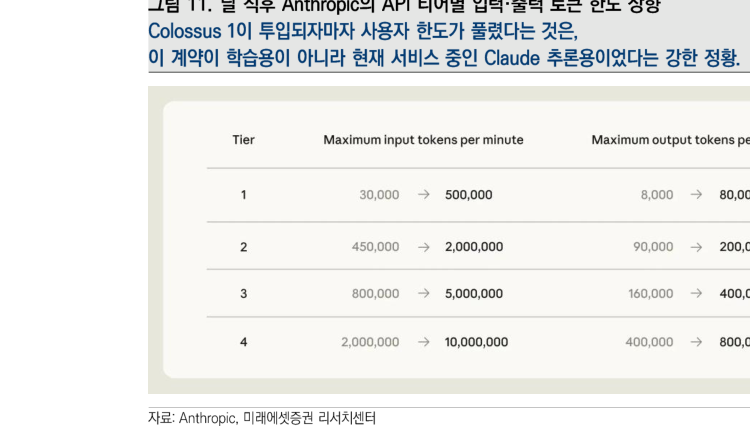
具体来看,以 Tier 4 为例,每分钟最大输入 token 从 200 万增加到 1000 万,提升 5 倍;输出 token 从 40 万增加到 80 万,提升 2 倍。Tier 1-3 也都出现了压倒性的限额上调。
这个变化的含义并不简单。它相当于承认:此前 Claude 并不是推理能力不足,所以才限制用户;而是纯粹因为可用硬件不足,连既有用户都无法充分服务。4 月 Pro 计划中悄悄移除 Claude Code、新用户 2 倍价格 A/B 测试、Opus 4.6 被怀疑 inference compute 不足等一系列不一致行为,都在这次事件中汇聚到同一个事实:Anthropic 缺的不是需求,而是可用推理算力。
4. 财务工程的双赢:60 亿美元对冲与 150 亿美元 ARR
(1) xAI 侧:用单一合同对冲运营亏损
这项租赁合同对双方都有重要财务含义。先看 xAI 的收入结构。假设 H100 15 万块,每小时 2.30 美元;H200 5 万块,每小时 2.60 美元;GB200 2 万块,每小时 5.00 美元。按加权平均租赁价格计算,就可以得到小时收入。
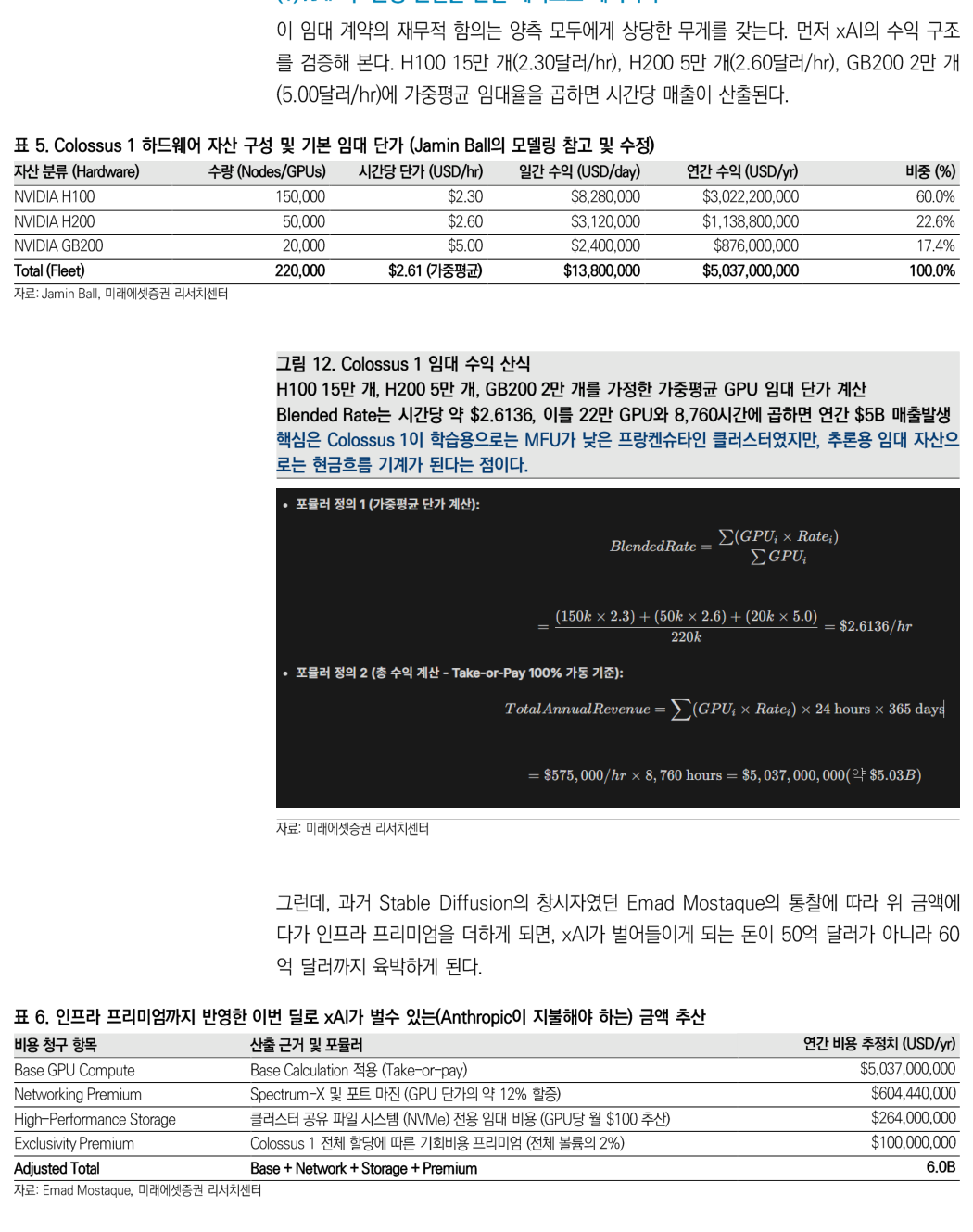
按基础计算,Colossus 1 全 fleet 的加权平均价格为每小时 2.61 美元,日收入约 1380 万美元,年收入约 50.37 亿美元。其中 H100 年收入约 30.22 亿美元,H200 约 11.39 亿美元,GB200 约 8.76 亿美元。
再按照 Stable Diffusion 创始人 Emad Mostaque 的思路,把基础设施溢价加进去,xAI 能赚的钱就不再只是 50 亿美元,而是接近 60 亿美元。溢价包括 Spectrum-X 与端口利润带来的网络溢价、集群共享文件系统等高性能存储费用,以及 Colossus 1 整体独占分配带来的机会成本溢价。
这 60 亿美元的重量,需要放到 xAI 的损益表里看才更清楚。按 2026 年一季度的净亏损年化,xAI 年化净亏损约为 60 亿美元。也就是说,把 Colossus 1 租给 Anthropic 所产生的每年 50-60 亿美元收入,几乎刚好覆盖 xAI 的亏损。xAI 仅靠这一笔交易,就接近盈亏平衡。
这会成为 SpaceX AI IPO 前非常关键的财务防守逻辑。从资本成本角度看,如果形象能从「烧钱研究所」变成「每年稳定产生 60 亿美元收入的基础设施收费站」,IPO 氛围本身就可能发生变化。
(2) Anthropic 侧:50 亿美元支出,150 亿美元 ARR
交易另一边,是 Anthropic ARR,也就是年化经常性收入的爆发效应。Dario Amodei 曾在播客中谈到过计算支出的 50:50 分配。如果整个行业计算支出为 1000 亿美元,其中 500 亿美元会投入推理。他还提出,这 500 亿美元推理计算支出,可以按比例转换为 1500 亿美元收入。把这个框架套到本次交易中,就会得到下表中的计算。
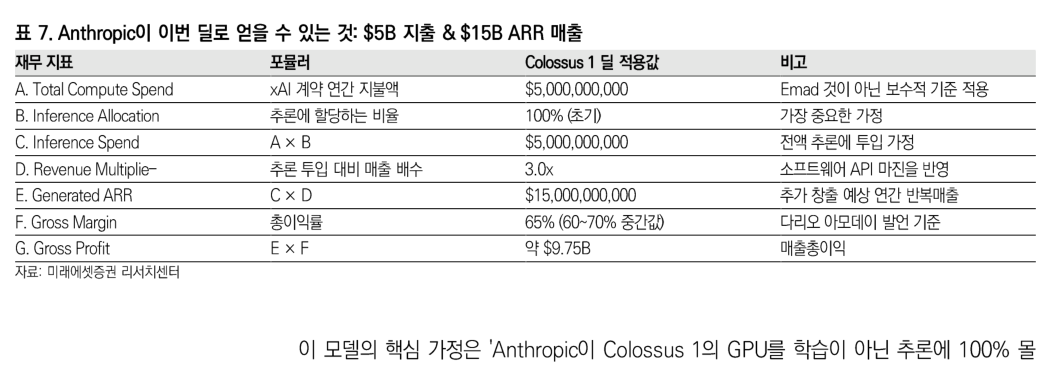
这个模型的核心假设是:Anthropic 会把 Colossus 1 的 GPU 100% 用于推理,而不是训练。这个假设已经基本被 Anthropic API 限额上调,以及 Claude Code 每 5 小时限制翻倍所验证。Colossus 1 的可用容量并没有被投入下一代模型训练,而是立刻被投入当前线上模型的推理基础设施。
还要同时看 Anthropic 至今的 ARR 轨迹。Anthropic 从 2024 年 2 月 ARR 1 亿美元,增长到 2026 年 5 月约 440 亿美元。18 个月增长 440 倍。更惊人的是,其 doubling 周期越来越短。从 1 亿美元到 10 亿美元花了一年;从 10 亿美元到 40 亿美元花了 3 个月;从 40 亿美元到 140 亿美元花了 4 个月;从 140 亿美元到 440 亿美元花了 5 个月。即便基数变大,连续翻倍的速度仍然没有明显放慢,这在任何规模的收入增长中都很罕见。Colossus 1 可能带来的 150 亿美元新增 ARR,有机会把这条曲线在年底前再推陡一次。

当然,前沿 AI 公司即使收入爆发,也会因为模型训练成本而长期承受盈利压力。因此,Anthropic 的赌注是:算法效率会持续提升,压缩每 token 训练成本;同时,已部署模型的收入会复利增长,最终在 2029 年左右走向盈利。
所以 Anthropic 首先必须维持这种爆炸式增长才能活下来。它所面对的是一种结构性压力:「不增长就会死,没有算力就无法增长。」因此,Colossus 1 带来的 150 亿美元 ARR 不是可有可无的附加项。这也解释了为什么 Anthropic 在模型层与 Musk 直接竞争,却在基础设施层不得不与他握手。
5. 「矮人与精灵」的大联盟:指向 OpenAI 的矛尖
(1) 两个异质族群为什么坐到同一张桌子前
到这里,一个问题自然浮现:Elon Musk 与 Dario Amodei 在理念上原本几乎不可能坐到同一张桌子前。那这笔交易是怎么发生的?
Musk 是挖地道、开熔炉、把巨大金属物体发射到太空的人。他更像一个工程匠人,崇尚用物理法则和 brute-force 去解决问题,也崇尚不受控制的自由。相对地,Dario 代表的是 Constitutional AI、有效利他主义、模型安全与 alignment。他更重视安全网与控制。
两人对 AI 的理解完全不同。Dario 一直担忧甚至有些轻视 Musk 的鲁莽速度和管理方式;Musk 则认为 Dario 的过度控制反而可能对人类危险。从 PMF 角度看,xAI 切向图像和视频生成这样的 B2C 场景,Anthropic 则集中在 B2B 编码。无论从理念还是市场定位,他们原本都是不该混在一起的两类玩家。
但这个联盟之所以能成立,原因只有一个:双方都出现了共同敌人。这个敌人就是 OpenAI。
(2) 法庭上的屠杀:OpenAI 的道德与法律破产
在 5 月 6 日 Colossus 1 交易达成前几天,Elon Musk vs Sam Altman 的诉讼中,OpenAI 的道德与法律正当性已经出现被单方面击穿的场景。可以把法庭进展概括为三记重击。
第一,程序性失败与舆论战失败。OpenAI 律师团队试图把一条私人消息以 Greg Brockman「口头回忆」的形式传递给陪审团,称 Musk 曾逼迫和解,并威胁说「这个周末之后,你和 Sam 会成为美国最被讨厌的人」。但法官立即驳回,并批评 OpenAI 一方:Musk 还在证人席上时你们不直接问,现在才想对陪审团耍花招。于是标题从「Musk 的威胁」变成了「OpenAI 被驳回的小动作」。
第二,1000 万美元秘密忠诚度收买。最震撼的爆料来自 2017 年。当时 OpenAI 仍是慈善机构,由 Musk 出资。Sam Altman 用自己 Family Office 的 1000 万美元股权,秘密给了 Greg Brockman,也就是现在的 OpenAI 总裁。当 Musk 的资产管理人 Jared Birchall 发现此事并警告说「Greg Brockman 自然会因此对 Sam Altman 产生更强忠诚」时,Brockman 保持沉默。在法庭上,Brockman 的解释是「很难约到 Elon 的时间」。但这被解读为一个 smoking gun:Altman 为了排挤 Musk、推动 OpenAI 营利化,用自己的钱收买了核心管理层。
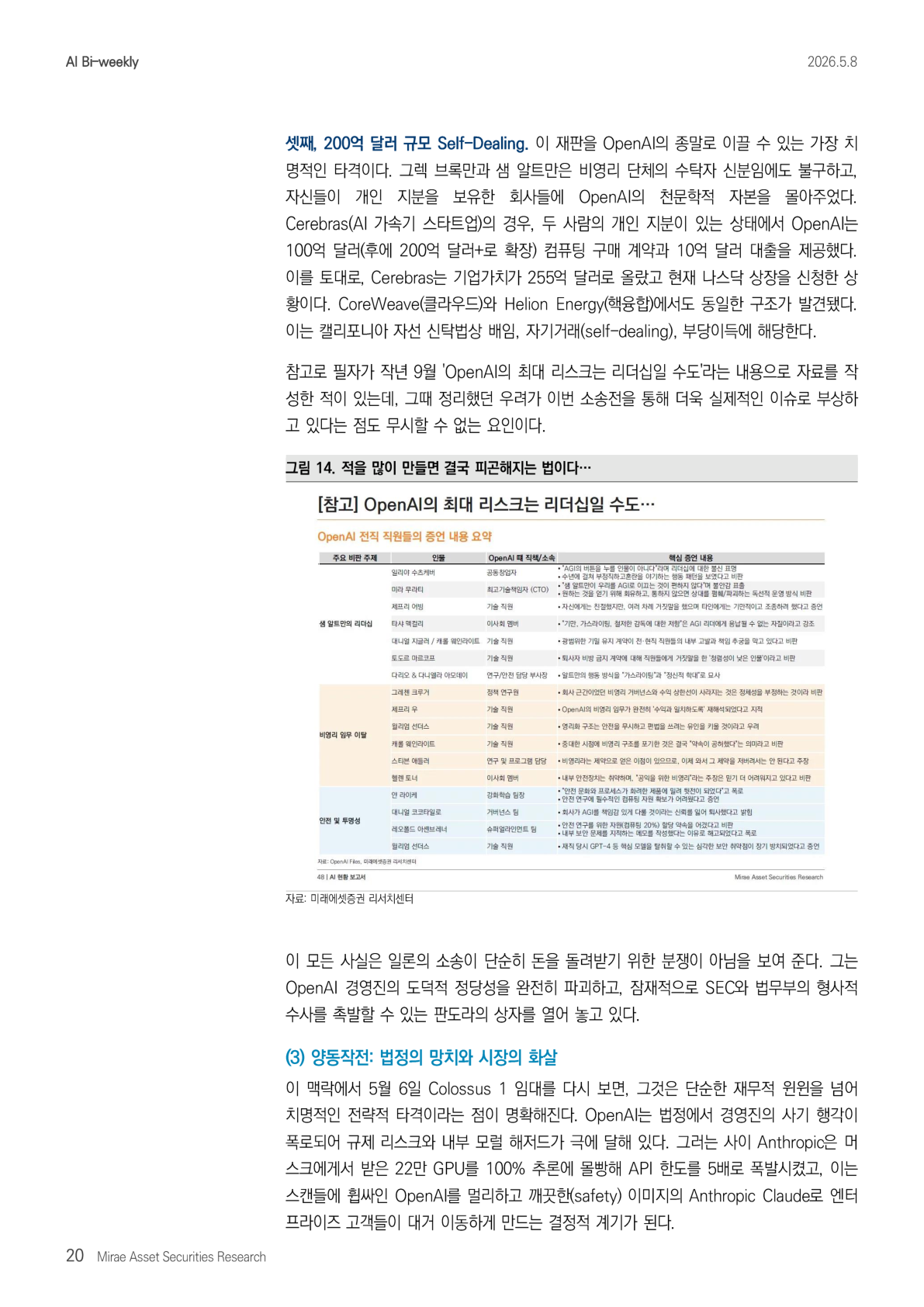
第三,200 亿美元规模的 self-dealing。这可能是把 OpenAI 推向终局的最致命打击。Greg Brockman 和 Sam Altman 身为非营利机构受托人,却把 OpenAI 巨额资本导向了他们个人持有股份的公司。以 Cerebras 这家 AI 加速器公司为例,在两人持有个人股权的情况下,OpenAI 向其提供了 100 亿美元,后来扩展到 200 亿美元以上的计算采购合同,以及 10 亿美元贷款。借此,Cerebras 估值升至 255 亿美元,并已申请纳斯达克上市。CoreWeave 和 Helion Energy 也出现了类似结构。按加州慈善信托法,这可能构成背信、自我交易和不当得利。
顺带一提,作者去年 9 月曾写过一份题为「OpenAI 最大风险可能是领导力」的材料,当时整理的担忧,正通过这场诉讼变成更现实的问题。
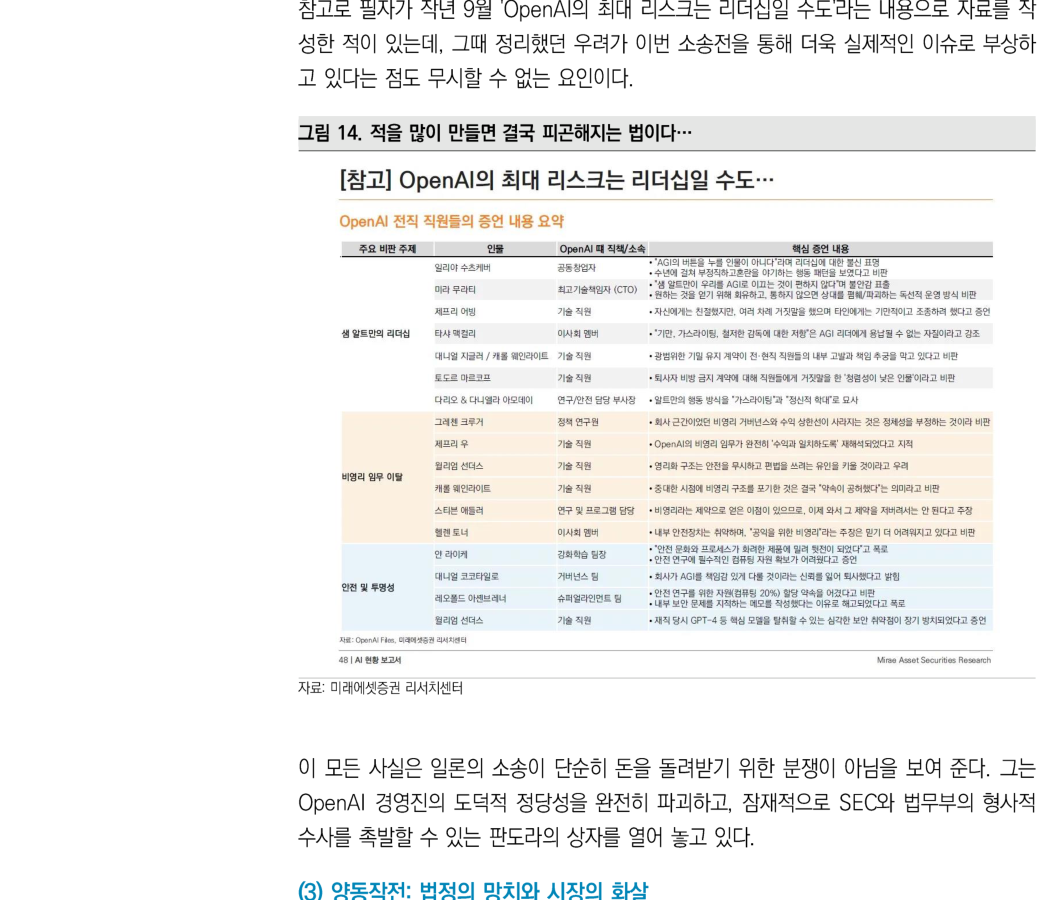
这些事实说明,Musk 的诉讼不只是为了拿回钱。他正在打开一个潘多拉盒子,试图彻底摧毁 OpenAI 管理层的道德正当性,并可能触发 SEC 与司法部的刑事调查。
(3) 双线作战:法庭的锤子与市场的箭
在这个语境下重新看 5 月 6 日 Colossus 1 租赁,就会发现它不只是财务上的双赢,更是一记致命的战略打击。OpenAI 在法庭上被曝光管理层问题,监管风险和内部道德风险都被推到高位。与此同时,Anthropic 用 Musk 交给它的 22 万块 GPU 100% 投入推理,让 API 限额爆炸式提升 5 倍。这可能成为企业客户远离丑闻缠身的 OpenAI、转向安全形象更干净的 Claude 的决定性契机。
总之,Musk 正在两个战场同时攻击 OpenAI。法庭上,他削弱 OpenAI 管理层的道德正当性;市场上,他武装 Anthropic,让它吸收 OpenAI 的收入和用户。当这套双线作战同时生效,OpenAI 的融资理由和用户信任都很难不出现裂纹。这也正是为什么两个原本截然不同的族群结盟,并不只是一个比喻。
6. 我们又一次必须提出的问题是:「谁握住了路口?」
在 4 月 24 日的报告里,作者给出的结论很简单:「从神话时代到算力时代。」神话里的主角是神,但神最终也不可能比石头,也就是硅,和闪电,也就是电力,更伟大。这个结论至今仍然成立。算力资源就是权力,这个命题没有改变。
但现在需要在这个结论上再加一层。5 月 6 日的 Colossus 1 租赁证明:算力资源握在谁手里,可能在短短一个月内被改写。市场再次确认,重要的不只是绝对资本规模,而是「谁在什么时间点握有什么」。
这次事件也说明,我们此前以 OpenAI / Anthropic / Google / xAI 四大玩家来理解 AI 市场,其实已经开始重组为联盟格局。一边是 OpenAI - Microsoft - Oracle 阵营,另一边是 Anthropic - AWS Trainium - SpaceX AI 阵营。
(1) OpenAI 还能反击吗?
MRC 这件新武器、30GW 路线图,以及 GPT-5.5 的压倒性性能,仍然是强牌。但法庭上正在崩塌的管理层道德正当性,以及资本募集理由,能否支撑这些强牌打到最后,仍是未知数。如果 Greg Brockman 与 Sam Altman 的交易丑闻、200 亿美元 self-dealing 最终引发 SEC 和司法部刑事调查,那么 30GW 路线图本身的资本募集也会动摇。
(2) 重新绘制受益者地图
在上一篇报告中,作者把 Amazon 和 NVIDIA 列为核心受益者。Amazon 同时支持 OpenAI 与 Anthropic 的计算,拥有双重杠杆;NVIDIA 则拥有 token 级智能密度最高的芯片,也就是最好的武器。这个结论现在仍然有效。但这次事件之后,受益者地图还应该新增两个坐标。
首先是 SpaceX。通过这笔交易,SpaceX 不再只是航天发射公司,而获得了「转型为 hyperscaler 的太空公司」身份,也就是一种新的 neo-cloud 业务形象。如果 6 月 IPO 正式化,市场会如何给这个身份定价,会非常值得观察。更重要的是,这笔交易向市场证明了一件事:一个烧下巨额 capex 的公司,可以把资产快速转换为现金流。
同样逻辑下,Meta 也值得继续关注。Meta 每次发布季度业绩,都会被投资者质疑 capex 是否过高。但 SpaceX AI 用一天时间就把物理资源转化为 60 亿美元租赁合同的案例,正在教育市场:拥有巨大基础设施的公司,总能以某种方式把资源外租,转换成现金流。市场对 Meta 是否也能走同一条路的认知,可能会逐渐转向更友好。
此外,在这个「算力时代、联盟时代」下,过去受到担忧的 neo-cloud 经营者,比如 CoreWeave、Nebius 等,其增长焦虑也可能被一定程度稀释。毕竟算力仍在持续被证明是瓶颈,因此过去难以想象的合纵连横才会不断出现。
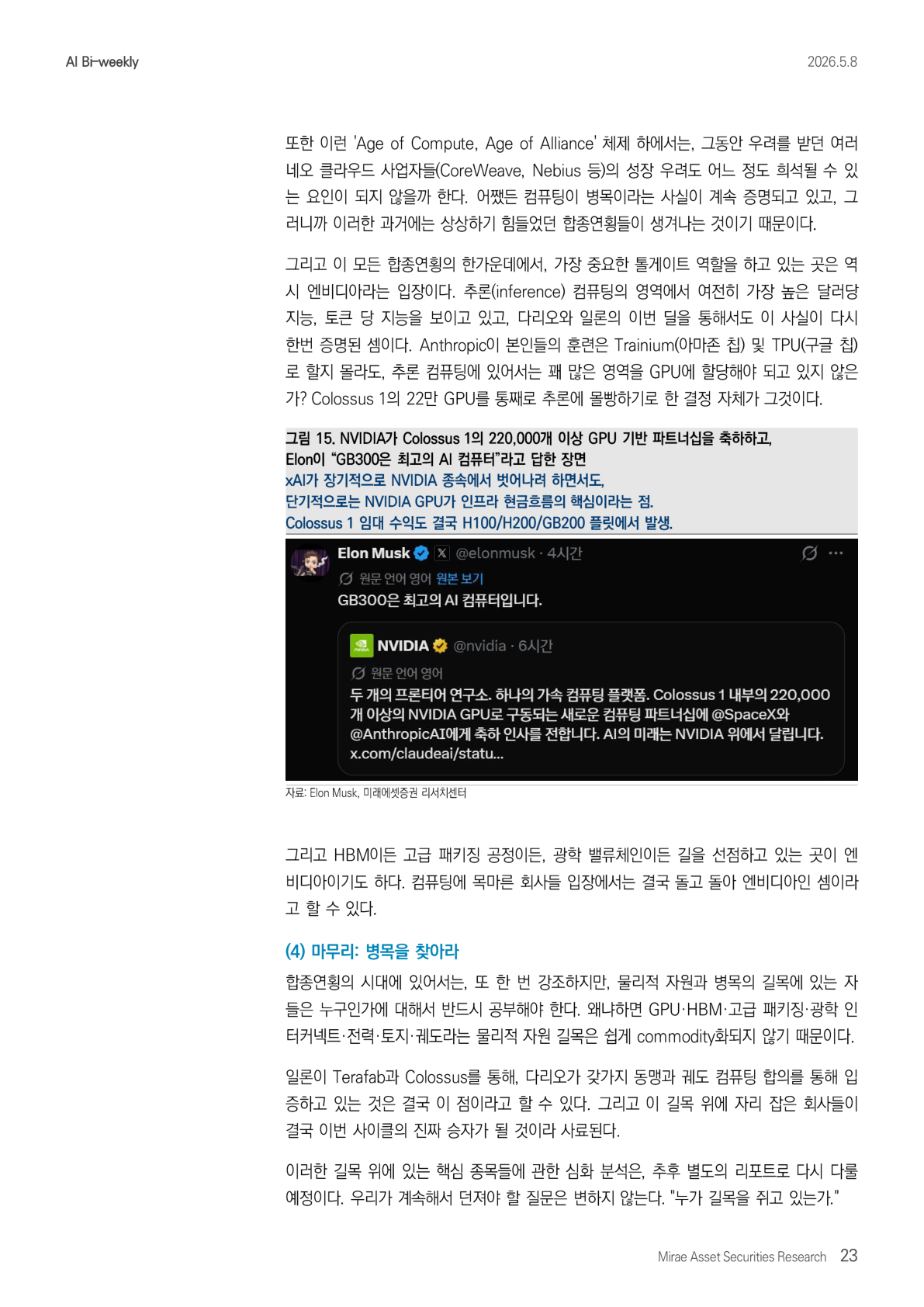
而在所有合纵连横的中心,最重要的收费站仍然是 NVIDIA。至少在推理计算领域,NVIDIA 仍然体现出最高的每美元智能、每 token 智能。Dario 与 Musk 的这笔交易也再次证明了这一点。Anthropic 也许会把训练交给 Trainium,也就是 Amazon 芯片,或者 TPU,也就是 Google 芯片;但推理计算中,它仍必须把很大部分分配给 GPU。把 Colossus 1 的 22 万块 GPU 整体投入推理,本身就是证据。
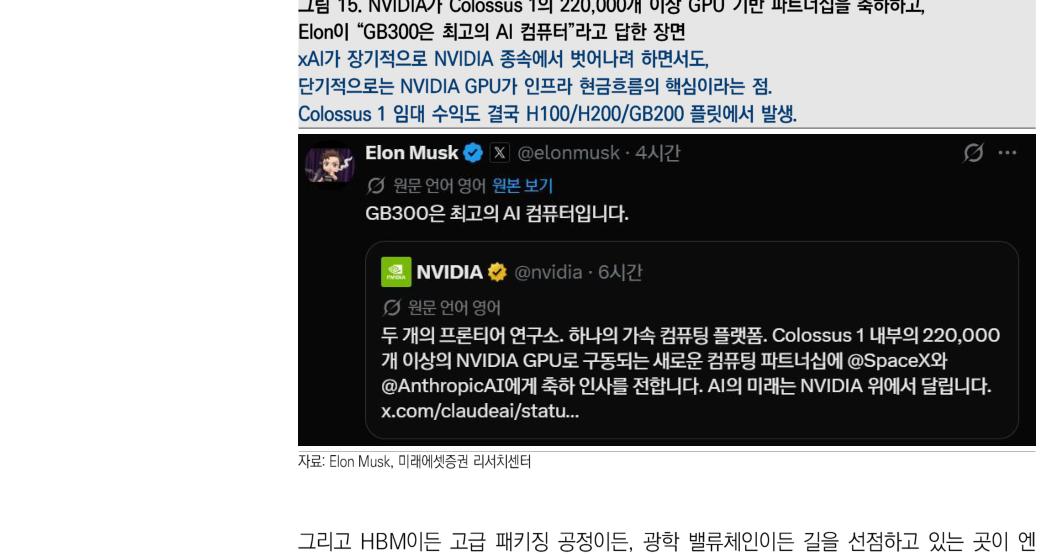
无论是 HBM、高级封装,还是光学价值链,NVIDIA 都已经站在路口。对于渴求算力的公司而言,绕来绕去,最终还是会回到 NVIDIA。
(3) 结语:寻找瓶颈
在合纵连横的时代,我们必须再次强调:要研究谁站在物理资源和瓶颈的路口。因为 GPU、HBM、高级封装、光互联、电力、土地、轨道这些物理资源路口,不会轻易 commodity 化。
Musk 通过 Terafab 和 Colossus 证明的,Dario 通过各种联盟和轨道计算协议证明的,最终都是这一点。站在这些路口上的公司,才会成为这一轮周期真正的赢家。
关于这些路口上的核心标的,作者将在未来单独报告中继续深入分析。我们需要持续追问的问题没有变:「谁握住了路口?」
原始版面备查
下面保留本篇译文对应的原报告页图,方便回看版式、图表和上下文。